import pandas as pd
with open('data/song_rank.csv') as f:
p = pd.read_csv(f)
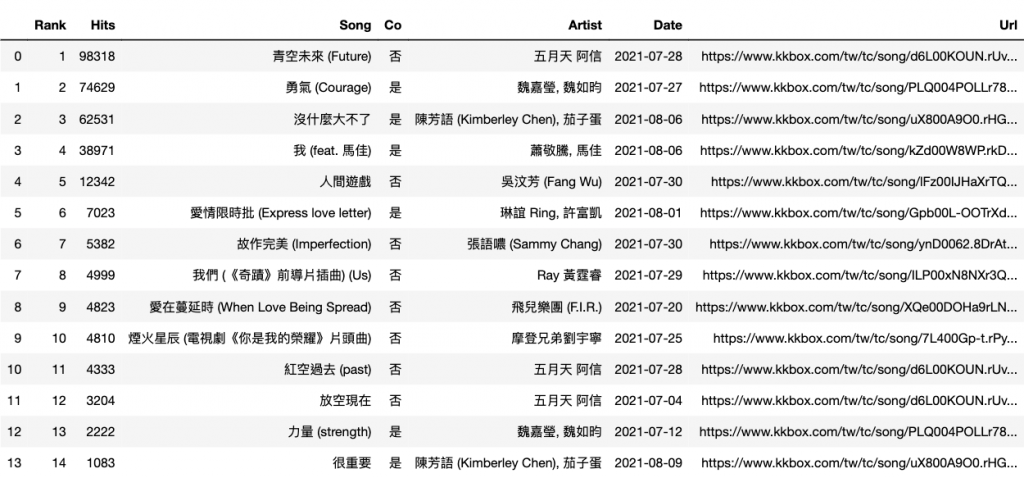
p
# 1. 列數 欄數 .shape
p.shape
(10, 7)
# 2. 簡要資訊 .info( )
表格結構: 類型,筆數,欄數,各欄型態
p.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10 entries, 0 to 9
Data columns (total 7 columns):
Rank 10 non-null int64
Hits 10 non-null int64
Song 10 non-null object
Co 10 non-null object
Artist 10 non-null object
Date 10 non-null object
Url 10 non-null object
dtypes: int64(2), object(5)
memory usage: 688.0+ bytes
# 3. 欄位型態 .dtypes
p.dtypes
Rank int64
Hits int64
Song object
Co object
Artist object
Date object
Url object
dtype: object
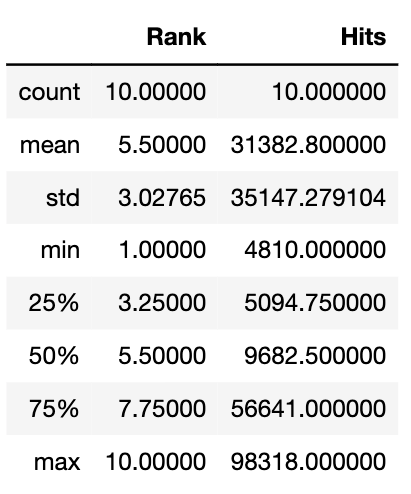
# 4. describe( ) 統計資料(only for數值)
個數, 平均數,標準差, min,第1分位,中位數,第3分位,max
p.describe()
p.columns
Index(['Rank', 'Hits', 'Song', 'Co', 'Artist', 'Date', 'Url'], dtype='object')
p.Rank #p['Rank']
0 1
1 2
2 3
3 4
4 5
5 6
6 7
7 8
8 9
9 10
Name: Rank, dtype: int64
type(p.Rank)
pandas.core.series.Series
p.Artist
0 五月天 阿信
1 魏嘉瑩, 魏如昀
2 陳芳語 (Kimberley Chen), 茄子蛋
3 蕭敬騰, 馬佳
4 吳汶芳 (Fang Wu)
5 琳誼 Ring, 許富凱
6 張語噥 (Sammy Chang)
7 Ray 黃霆睿
8 飛兒樂團 (F.I.R.)
9 摩登兄弟劉宇寧
Name: Artist, dtype: object
type(p.Artist)
pandas.core.series.Series
dtypes:
getwd()
setwd('/Users/carplee/Desktop/untitled folder/')
r = read.csv('data/song_rank.csv')
##### 看整個表格長怎樣 ####
#str()表格結構:類型,筆數,欄數,各欄型態,值
str(r) #base
#summary()統計資料:Min,第1分位,中位數,平均數,第3分位,Max
summary(r)
#### 看每一欄長怎樣 ####
colnames(r)
r$Rank
class(r$Rank)
# [1] 1 2 3 4 5 6 7 8 9 10
# > class(r$Rank)
# [1] "integer"
#### 數值向量 ####

